Arabic LLM Benchmark
Introducing the Arabic Broad Benchmark - ABB is the standard benchmark used on the ABL Leaderboard, where you can discover the rankings of all Arabic models

The Arabic Broad Benchmark (ABB), developed by SILMA.AI, is a comprehensive dataset and evaluation tool designed to assess Large Language Models (LLMs) in Arabic. It features 470 high-quality, human-validated questions drawn from 64 datasets, covering 22 categories and skills. ABB uses a specialized benchmarking script that combines 20+ manual rules and customized LLM-as-Judge methods for precise evaluation. It serves as the official standard for the ABL Leaderboard, which ranks Arabic LLMs
Explore Benchmark & Leaderboard
Explore Benchmark & Leaderboard
Benchmark Features

A groundbreaking advancement in Arabic LLM evaluation, ABB fills critical gaps in the landscape with a new gold standard for benchmarking
Key Highlights
Human-Validated, Broad-Coverage Dataset
Enables more reliable and comprehensive evaluation of general Arabic language proficiency
Hybrid Evaluation Methodology
Combines rule-based accuracy with the scalability of LLM-as-judge assessments for nuanced and scalable scoring
Next-Generation Leaderboard
Features advanced tools like contamination detection, standardized speed metrics, and sub-leaderboards by model size and skill—setting a new benchmark for transparency and utility
ABB equips researchers and practitioners with the tools to evaluate, compare, and select Arabic LLMs with unmatched precision—driving more transparent, rigorous, and informed development across the NLP ecosystem
Explore Benchmark Dataset
Explore Benchmark Dataset
Leaderboard Features
Size-Based Leaderboards
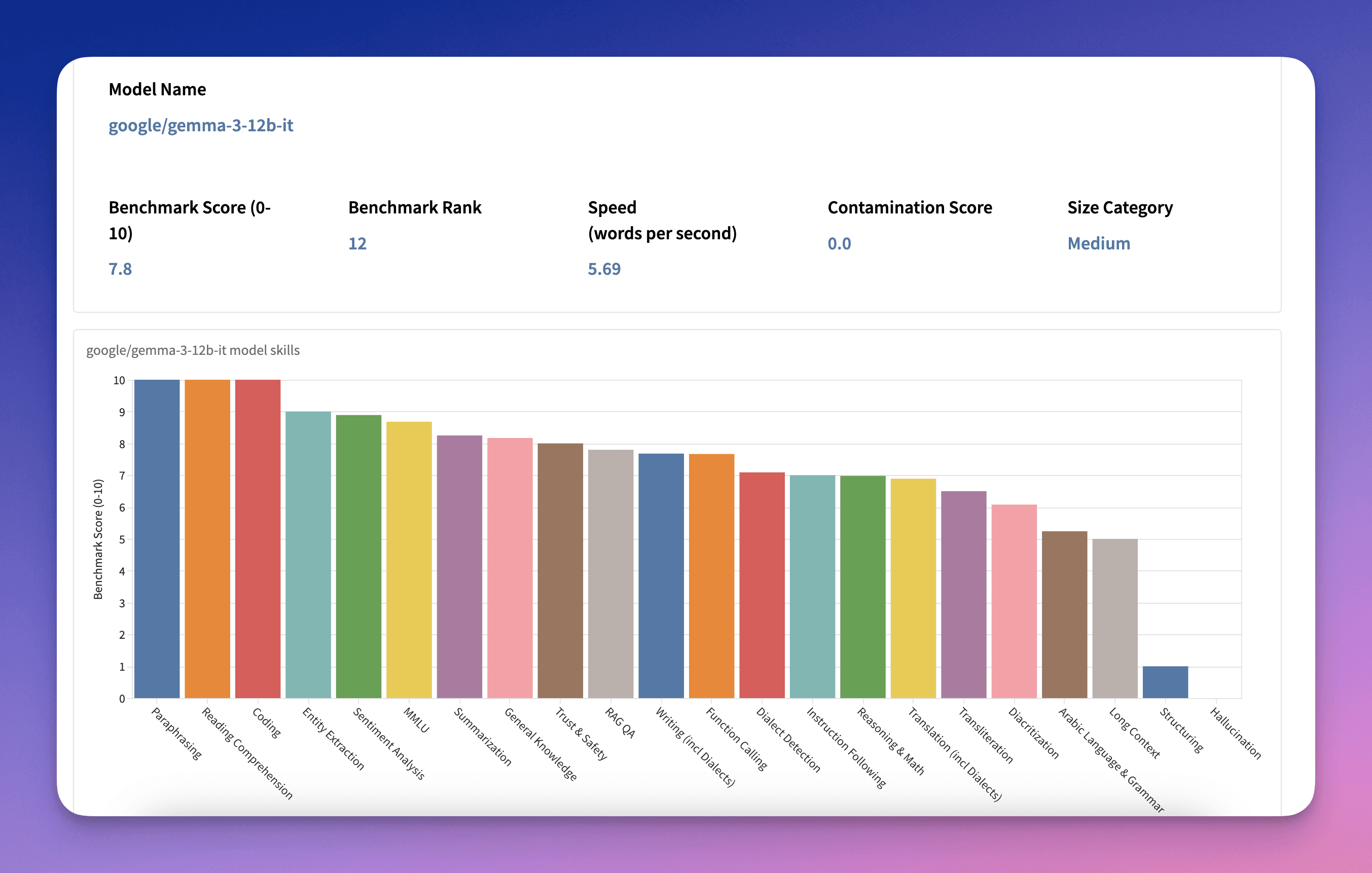
Dedicated leaderboard sections allow users to compare models by size, answering questions like: “What’s the top Arabic model under 10B parameters?”
Defined size categories:
Nano: Fewer than 3.5 billion parameters
Small: 3.5 to 10 billion parameters
Medium: 10 to 35 billion parameters
Large: More than 35 billion parameters
Skill-Based Leaderboards
Additional sections enable model comparisons based on specific capabilities. For instance, identifying the best Arabic model for handling long-context inputs.
Visual Comparison
Models can be evaluated side by side using radar charts to visualize their performance across different skills.
Deep Dive
These reports offer a focused analysis of a single model, highlighting its strengths and weaknesses. Full output samples are included for transparency.
Speed
Model performance is evaluated in terms of generation speed, measured in words per second. This is calculated by dividing the total words generated during testing by the elapsed testing time in seconds.
To ensure consistency, all models on Hugging Face are benchmarked using the same hardware setup: an A100 GPU and a batch size of 1. For models with over 15 billion parameters, multiple GPUs are used.
Speed comparisons are valid only within the same size category. Closed or API-based models are only compared with other API models, as they are evaluated externally.
Contamination Detection
We employ a proprietary method to estimate the likelihood that a model was exposed to test data during training. This results in a contamination score, which is displayed alongside the model's output, marked with a red indicator.
To preserve leaderboard credibility, strict policies are in place to prevent repeated model evaluations. Each organization or account is restricted to one submission per month.
To avoid score manipulation, we keep details of the detection algorithm, contamination threshold, and sub-threshold scores confidential.
Any model found with signs of contamination is immediately removed and reviewed. Additionally, a banning system is enforced to deter misuse.
Explore Leaderboard
Explore Leaderboard